

More on Technology
Innominds and Qualcomm Collaborate to Drive Enterprise Digital Transformation with High-Compute Edge AI Platform
-
Team Eela

Data Lake is quite similar to what its name suggests. Its a big data storage which consists of a huge amount of unrefined data in its natural or raw form, which could be structured, semi-structured, and unstructured. It offers data integration from various input sources without any need of pre-processing the data for ingestion. It is an ideal choice for storing vast data from multiple sources and storing them in raw or natural format.
Data ingested in the Lake can be transformed later upon the requirement, which is quite useful for high-speed data sources. Data lake also supports various analytical tools and software needed for insights, decision-making, and other business requirements.

Generating the business values from the data is the key to make or break from the competition. An Aberdeen survey* showed that the companies implementing the data lakes can easily outperform their competition by 9% in organic growth revenue. The added benefits of using various analytical tools like machine learning in varieties of structured and unstructured data opens a whole new window for R&D Innovations.
It helps organizations draw better insights and predictions of the market and its users’ choices, making them make better decisions, resulting in delighting the customers. This creates new customers and helps to retain them and make them their promoters as well.
Data Lake concept is comparatively new but an emerging technology in the market. There are significant benefits and key advantages of data lake that many organizations are using it on a larger scale. It is solving many problems that were impossible before on Data warehouses.
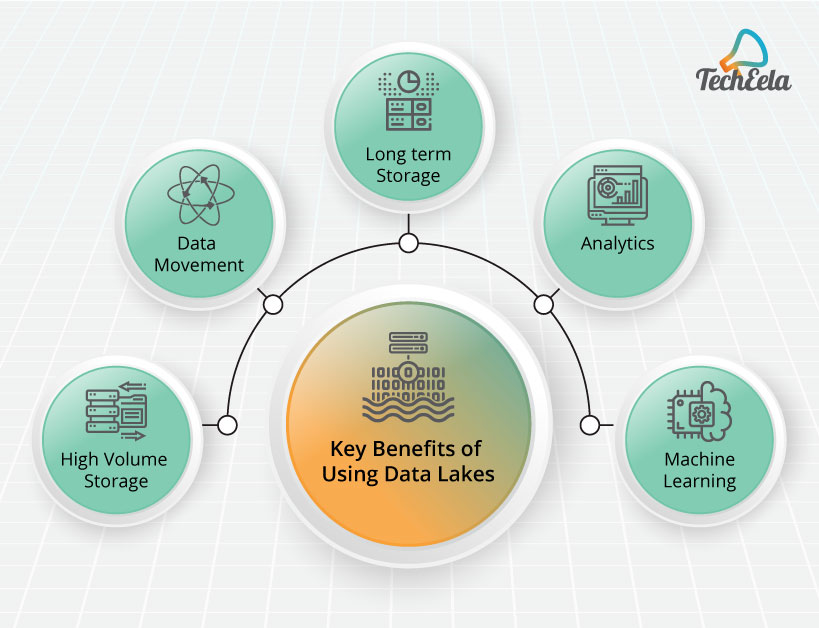
Some of the Key Benefits of using Data Lakes are:
Data Lakes have an added benefit of scalability because of being unstructured. They can handle the growing amount of data and that’s why they are being used for the data sources that are producing the enormous amount of data. Example of these Big Data lakes includes website activity logs, social media analytics, buying history, IoT devices data, etc.
Extracting the high-speed data from sources using various tools like Kafka, Scribe, etc. makes it best for multiple high-speed sources. These Data sets must be loaded as quickly as possible in their original format. Doing this, makes the data lakes highly flexible storage solutions suitable for both high-speed sources and multiple independent sources.
Data Lakes are open source and competitively priced as well. It makes them a good storage option for long-term storage of data for any organization. Organizations which utilize the long historical data for their analytics are most benefitted.
The ability to run analytics using tools and frameworks (Schemas) of any choice without moving the data to a separate analytics system makes it a perfect choice for data scientists, data analyst, data developers and business analysts. It helps improve the company’s R&D Innovations, as they can access enormous data sets without worrying for its pre-processing and use them without moving them to some other system.
The ability to train the machine learning and AI models on Data Lakes helps the models learn and solve various issues resulting from the unstructured nature of Data Lakes. This also makes them a perfect playground for data scientists and allows them to develop their own analytics. It also allows various organizations to produce insights and forecast likely results, optimizing an organization’s journey.
The importance of data is already well known in the companies, and its exponential growth is making its storage and organization a big problem to solve. Data warehouse and Data Lake are two different approaches for solving the big data storage problem.
Let us take you through both of them, one by one –
The main difference between the Data Lake Vs Data Warehouse is the method of ingesting the data. Data warehouse follows the ETL (Extract, Transform and Load) process whereas Data Lake follows the ELT (Extract, Load and Transform) process i.e., here the Data is uploaded first and is processed on-demand by various specialist tools, which is known as schema-on-read.
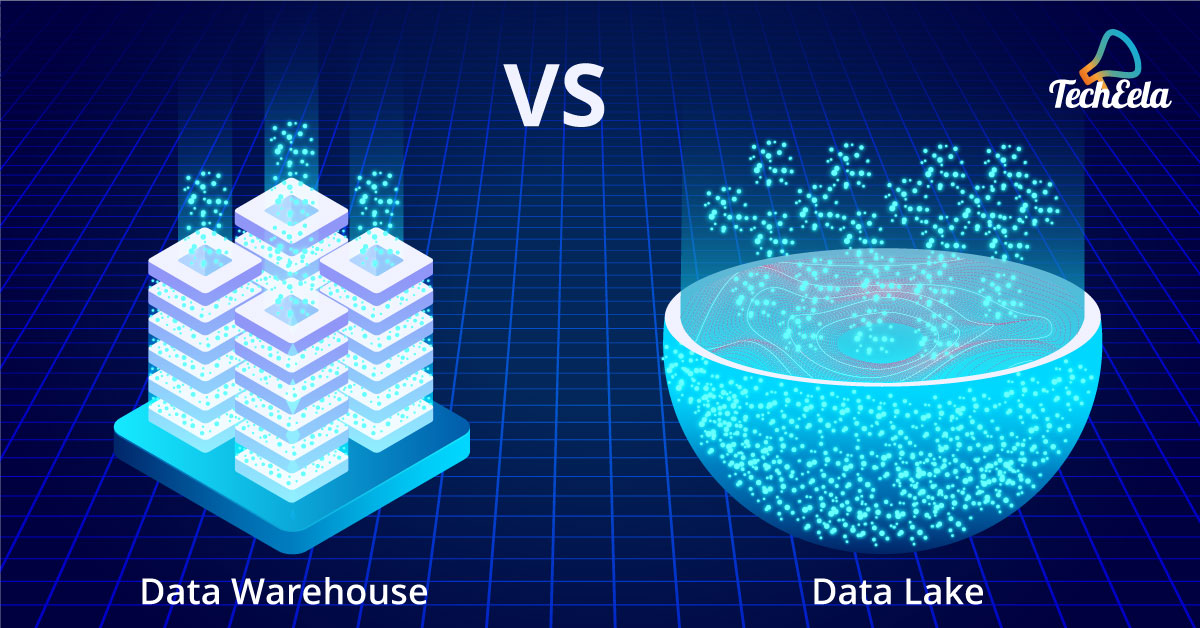
In contrast to this, a Data warehouse follows the schema-on-write means, the data extracted will be transformed as per the schema present for the data, afterward, the data is loaded. A data warehouse primarily handles structured data sets like relational database and operation database, and it is ready for immediate use without further processing.
Due to being highly structured the data quality is very good and query results are fastest, but it does use the high-cost storage as well.
The downside of the Data Warehouse is that it is not scalable for collecting the data from multiple data sources as the pre-processing will make the ingestion slow and is not suitable for real time data storage and analysis, this is where the Data lakehouse solution came into picture, by loading the data first and then it is transformed as per the demand. In simple words we can say that Data Warehouse works on the principle ” Think First Load Later” and Data Lake works on the principle “Load First Think later”.
Data Lake is centred around quantity whereas Data Warehouse is centred around quality, they are not competitors to each other but are required as per the needs of the organizations. Both offers some unique advantages and disadvantages of their own, which is to be taken into consideration and utilize as per the needs. Following is the representation of Data warehouse Vs Data Lake.
| Data warehouse | Data Lake |
|---|---|
| Relational database, operational databases, and line of business applications | Non-relational and relational from web sites, mobile apps, social media, and corporate applications |
| Schema on-write. | Schema on-read. |
| High-cost storage | Low-cost storage |
| High level of data curation | Any data (may or may not be curated) |
| Used by business analysts using BI and visualizations. | Used by data scientists, data developers and business analysts using ML. |
Implementation of the Data Lake Architecture depends on the various technologies and purposes for which it is used. It can be done in Cloud and on-premises. On-premises-based data lakes can be difficult to scale and are expensive too. Large on premise-based solutions usually face tightly coupled storage and compute, due to which there is wastage of resources.
On the other side Cloud-based repositories are a much better option because they are economical. Companies more commonly use cloud-based repositories as they have multiple choices and support from various service providers like Amazon AWS, Microsoft Azure, Google Big Query and many other platforms.
Data lakes operate on three principles majorly. Three Cs of operation in data lakes are:
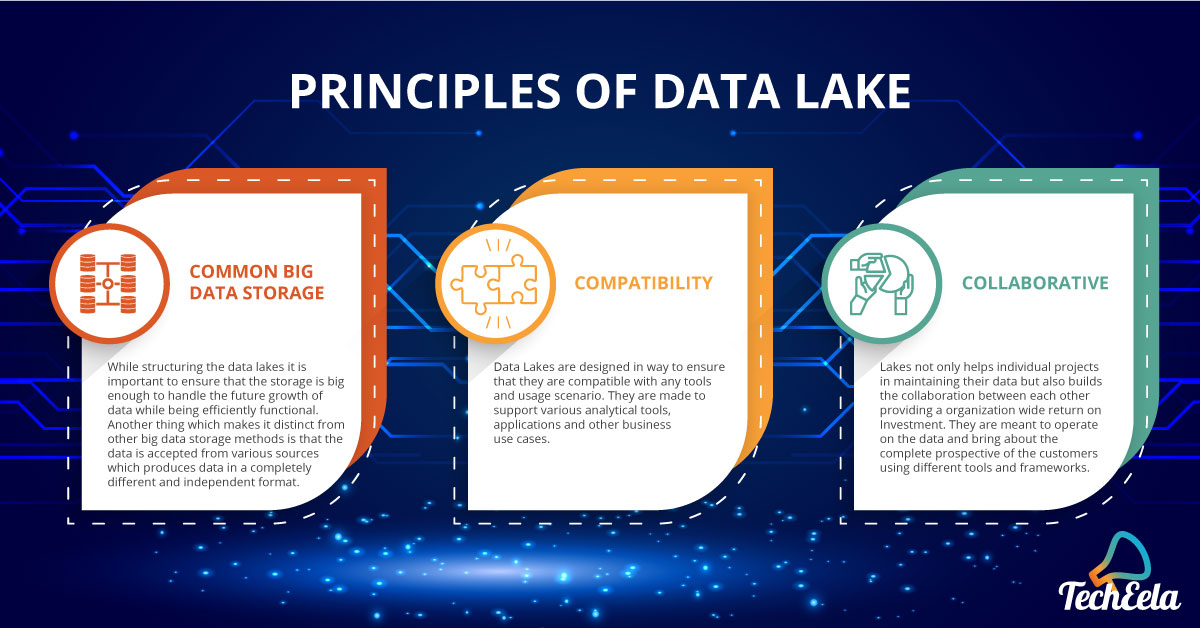
Another thing that is important while implementing the lakes is defining a proper schema for the transformation of the data to achieve optimal analysis down the line. It is also important to define a proper hierarchy and searchable catalogue of the data to keep track of them.
Despite having many advantages, Lakes does not always prove to be ideal in every scenario. There are some criticisms around the architecture, which are legitimate. Such as :
The aforementioned criticisms are not inherent flaws of Data Lakes, but they highlight the need of proper Data Governance policies for validation, proper Meta Data Management and planning for your enterprise data lake.
More on Technology


