

More on Technology
Innominds and Qualcomm Collaborate to Drive Enterprise Digital Transformation with High-Compute Edge AI Platform
-
Team Eela

Today, data holds great value in business organizations as having access to raw data can help enterprises enhance their customer-related services, improve their business processes, product development, and better decision-making. Data can be structured, unstructured and semi-structured.
Before we go deep into basics of data engineering and its solutions, first, let’s talk about engineering. Anything that we create, build or design is called engineering. Therefore, data engineering refers to the building creation and designing of data pipelines for the data scientists or data analysts to make use of that information. Data engineering revolves around converting the raw, unstructured data in a more usable form, so it becomes easier to create frameworks to work upon.
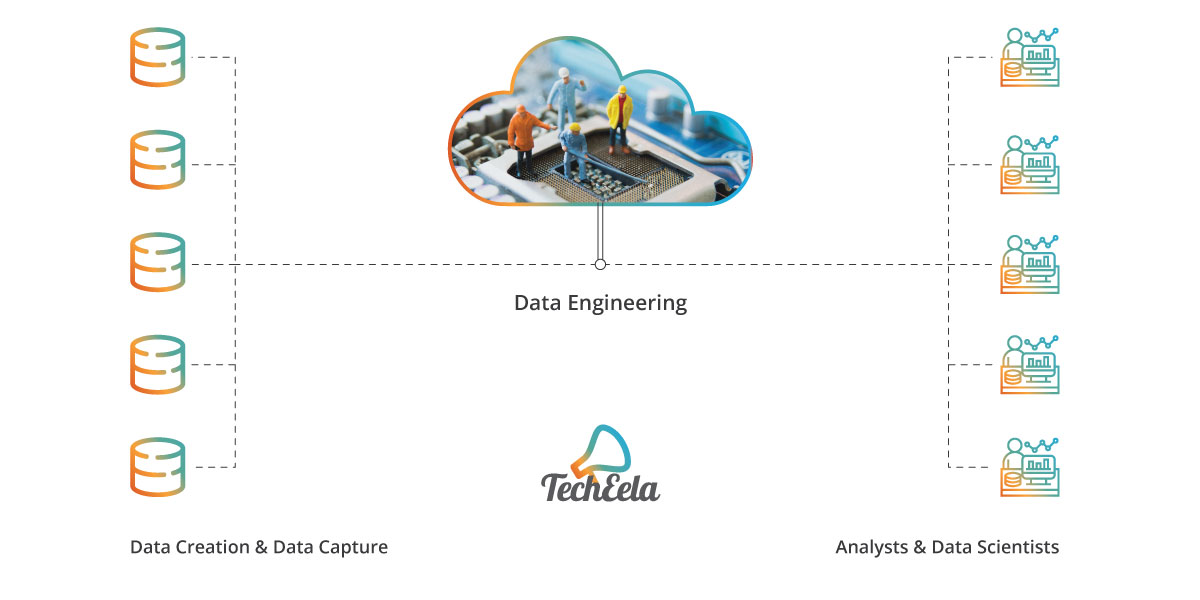
Data engineers are those people that we require to carry out tasks involved in data engineering. They are usually from IT or computer science. Data engineers help manage the raw data to make it accessible and usable. Data engineers know how to create value from raw and unstructured data and transport data from one place to another without any modifications. According to Dataquest, data engineers fall into three popular categories:
Generalists are usually found on small teams or in small companies. Here, data engineers perform various tasks as one of the few “data-focused” people. Generalists are often responsible for every step of the data process, from managing data to analyzing it. This is a good data engineering role for anyone looking to transition from data science to data engineering since smaller businesses won’t need to worry as much about engineering “for scale.”
Often found in midsize companies, pipeline-centric data engineers work alongside data scientists to help make use of the data they collect. Pipeline-centric data engineers need “in-depth knowledge of distributed systems and computer science,” according to Dataquest.
In larger organizations, where managing the flow of data is a full-time job, data engineers focus on analytics databases and data analytics tools. Database-centric data engineers work with data warehouses across multiple databases and are responsible for developing table schemas.
There are a certain number of skills that are required to be qualified as a data engineer such as:
Apache Hadoop and Apache Spark: The Apache Hadoop software library provides the user with a framework that helps with processing large data sets across clusters of computers using simple programming models. The software is built in a way that lets you reach from one server to thousands of multiple servers where each server provides storage. Python, Scala, Java, and R are some programming languages that are supported on the platform.
The processing speed in Hadoop is of great concern despite it being a very important tool in Big data. Apache Spark provides you with a data processing engine that can almost do the same tasks as Hadoop and supports stream processing, where continuous input and output of data is required. Hadoop uses batch processing where the data is collected in smaller batches and can be processed in bulk later which can make it a tedious process.
C++. C++ being a general-purpose language, makes it easier to use where the data can be managed and maintained easily and provides real-time analytics making it a powerful tool.
Database systems (SQL and NoSQL). SQL being the standard programming language, builds and manages the relational database systems (rows and columns are a part of these tables). The databases where no tables are there, i.e., non-tabular form are called NoSQL databases. They are available in different kinds according to their data model, it could be a graph or document. It is the duty of data engineers to know how to manipulate database management systems (DBMS). It is a software application where databases are provided with an interface for storing and retrieving information.
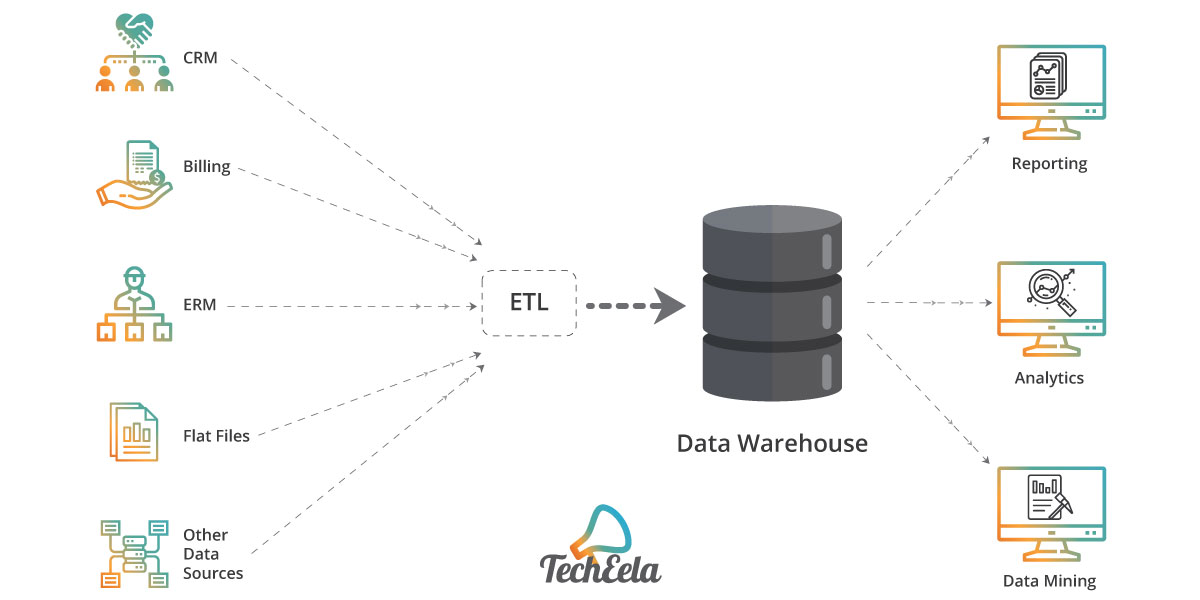
Data warehouses are a storage repository that stores data in large amounts, be it current or any time in history for data analysis. This data is sourced from various types of sources, such as a CRM system, accounting software, and ERP software. The business enterprises ultimately use this data for reporting, analytics, and data mining and other business-related tasks. Therefore, data engineers are expected to be familiar with Amazon Web Services or AWS, various data storage software and cloud services platform to perform the tasks mentioned above with data.
ETL is a process where the data is extracted from one source, then transformed into a readable format that for data analysis and storage in the data warehouses. Analyzing data that adheres to a particular business query uses ‘batch processing’ to help the end-user. ETL extracts the data from different sources, then a certain set of rules according to the requirements of the businesses are applied, and finally the converted data is then loaded into the database or a business intelligence platform so it is available for anyone and everyone in the organization always.
Algorithms in machine learning can also be referred to as models. Data scientists are able to predict the scenarios in data (current or previous) only because of these models. Data engineers are supposed to have a basic knowledge of machine learning as it helps them fulfill the requirements of data scientists and the organization. Data engineers are also responsible for the building and production of data pipelines which are more accurate with the help of these models.
The interface used by software applications for accessing data is known as an API. An API lets more than one machine or application converse with each other to finish a particular task. For example, let’s take the web applications that use API where they allow their front end who faces the user to communicate with the back-end data and functionality.
As soon a s request comes up on the website, the API permits the application to access the database, extract information from the required tables in the database, process the request and respond in an HTTP-based web template, which is finally displayed on the web browser. Data engineers build these APIs in the databases to help data scientists and data and BI analysts analyze and query the data.
Python is easily the most used programming language for statistical analysis and data modeling. Java is widely popular in creating frameworks for data architecture and most of their APIs created for Java.
Data engineers are supposed to have a sound knowledge of Hadoop. The Apache Hadoop software library consists of a framework that permits the distribution of processing of large data sets towards clusters of computers with basic programming models. It is designed in such a way that it goes from single servers to as high as thousands of machines, where each machine is offering storage and local computation. The most widely used tool for programming in data science is the Apache Spark. Scala is language in which it is written.
The primary focus of data engineers is usually on data filtering and data optimization, but a basic knowledge of algorithms is required to understand better overall data functioning in an organization, apart from this in order to define the checkpoints and end goals the knowledge makes it easier to solve the business-related obstacles.
Data engineering comes with particular responsibilities daily.
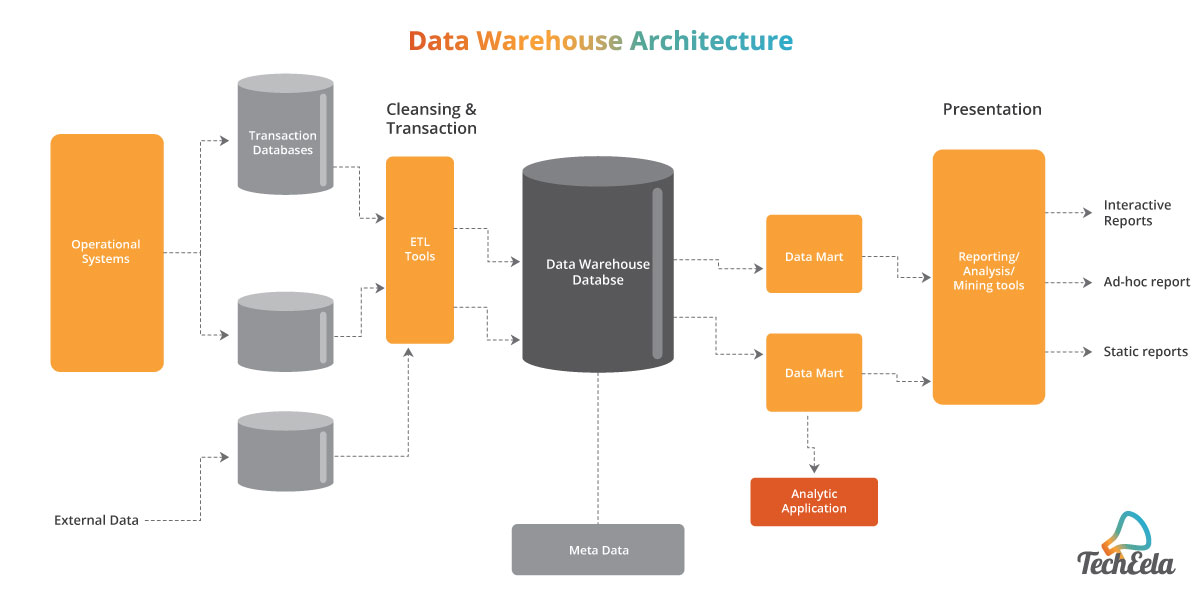
Data engineers mine through the data for insights and convert unstructured data into a more usable form for data analysts. They write queries, maintain the architecture and design of data and create data warehouses for large databases.
Data scientists on the other hand mine and clean unstructured data, create models to work on big data and analysis of big data.
While data analysts process data and provide summary reports. Gather information out of a database by writing queries. Use basic algorithms and have knowledge of statistics, data visualization and analysis.
Despite data engineering being a booming field, there are still a few challenges that data engineers face:
As the advancements in technology are increasing, data engineering is all set for a complete transformation as the current developments include Artificial intelligence, machine learning, serverless computing and hybrid cloud etc. The use of big data and various data science tools are going to increase in the coming years.
The shift from batch-oriented data movement and processing to real-time data movement and processing, we can see a transformation towards “real-time data pipelines and real-time data processing systems.”
Data warehoused have become very popular lately as they are flexible enough to house data marts, data lakes, or simple data sets based on need.
The following four areas have been earmarked as technology shifts in data engineering of the future:
Data engineering involves creating, designing, and building data pipelines and transforming data for a data science engineer/ big data engineer to make it more user-friendly. Data engineering mainly focuses on the practical implications of data science and is one step ahead of basic engineering data collection and analysis. Data engineering demands a specific set of skills and background to be an insight data engineer such as SQL, programming, Apache, Azure, ML etc. Data engineers are responsible for designing data architectures, developing data set processes, data modeling and mining.
Data engineers work closely with data scientists and data analysts and reform data before they can process data and design models to work on. Data warehouses and data lakes are extensively used to store big data. A data lake is a vast repository of raw and unstructured data, whereas data warehouses pool structures, filtered and processed data.
Data quality issues, data leaks and context switching are a few major challenges faced in data engineering. Even then data engineering is said to be a highly demanded field globally. It is ranked among the top jobs and data engineer salary has been scaling up highly. The future of data engineering is quite dynamic as it provides real-time data analytics and processing. In the coming times, there will be wide use of big data and other data science tools.
More on Technology


