

More on Technology
Innominds and Qualcomm Collaborate to Drive Enterprise Digital Transformation with High-Compute Edge AI Platform
-
Team Eela

DataOps, aka data operations is a process-oriented, agile, and automated methodology that focuses on data quality improvement, inculcates speed and reduces data’s cycle time. It is used by the data analytics and IT departments for managing and deployment of data.
DataOps is a cluster of various technical procedures, roadmaps, cultural standards, and frameworks that allows:
DataOps was initially implemented as best practices but nowadays, it is an advanced and important subset of data analytics and can also be taken as an individual approach towards analytics. As an expert one must even know more about this. It supports seamless communication between IT and analytics department in organizations. One of its main functions is to streamline how the data is managed and how the product designing is done.
The crux of DataOps lies in the alignment of the way enterprises manage their data and the goals they have for their data. The focus is on inculcating data strategy practices and procedures that help improve the efficiency, performance, and speed of analytics, comprising access to data, quality control, model deployment, integration, automation, and management.
According to data manifesto, there are 18 DataOps principles that must be followed:
First and foremost priority of an organization should be to satisfy their customers via faster and convenient delivery of important insights.
Data analytics’s performance can only be measured by the extent to which it delivers insightful data analytics, helps incorporate accurate and true data, and uses strong frameworks.
As the world is evolving, technology is also evolving, and so are the people’s need and requirements. Enterprises have to keep up with these ever-changing needs of the people and accept the change in the industry to have the edge over their competition. Face-to-face interaction is considered to be the most efficient, effective, and agile communication method with the customers.
All the teams are supposed to be in coordination with each other in order to achieve long term goals. Data analytics team will be overlooking a number of roles and have different preferred tools and software. This diversity will result in better productivity and performance.
Support teams, IT teams, data analytics and operations teams must all work in coordination and regularly cooperate when a project is on-going.
The best insights of data analytics tools, designing, new algorithms, customer requirements, and architectural needs are all believed to be self-organized.
As there is a high demand for data insights, the data teams should strive to have less fortitude or heroism and should work on building scalable procedures for data analytics teams.
Data analytics teams must self-reflect and introspect to improve their performance and efficiency at regular intervals and seek feedback from the customers and statistics.
Analytics department has several tools and software for integrating, accessing, visualizing, and modelling data. All these tools and software generates code that justifies the actions on data insights.
Orchestrating data, tools, analytics code, environments, and data teams work from start to end is important for achieving results.
Outcomes should be reproducible to have configurations of hardware and software, and specific configuration and code for specific tools are also required.
We believe it is important to minimize the cost for analytic team members to experiment by giving them easy to create, isolated, safe, and disposable technical environments that reflect their production environment.
To simplify things at work, one must not run behind technicalities and excellence but should include simplicity, which in turn means not overdo tasks and assignments.
Pipelines in data analytics correspond to manufacturing lines. The basics of DataOps is to lay emphasis on gaining efficient results in the manufacturing of data insights.
Data pipelines designed in an organization must have a built-in system for self-detection of errors or bugs or any other security related code in the data. They should always have regular feedback to avoid any malfunctions.
The main aim should be to keep a check on the performance, quality, and security in order to track any unexpected occurrences.
An especially important aspect of generating great manufacturing efficiency is to avoid reusing the earlier work by anyone in the organization.
The time and effort that is put in to develop a need of people into an idea, its production and operation and ultimately the consumption of the product should be reduced.
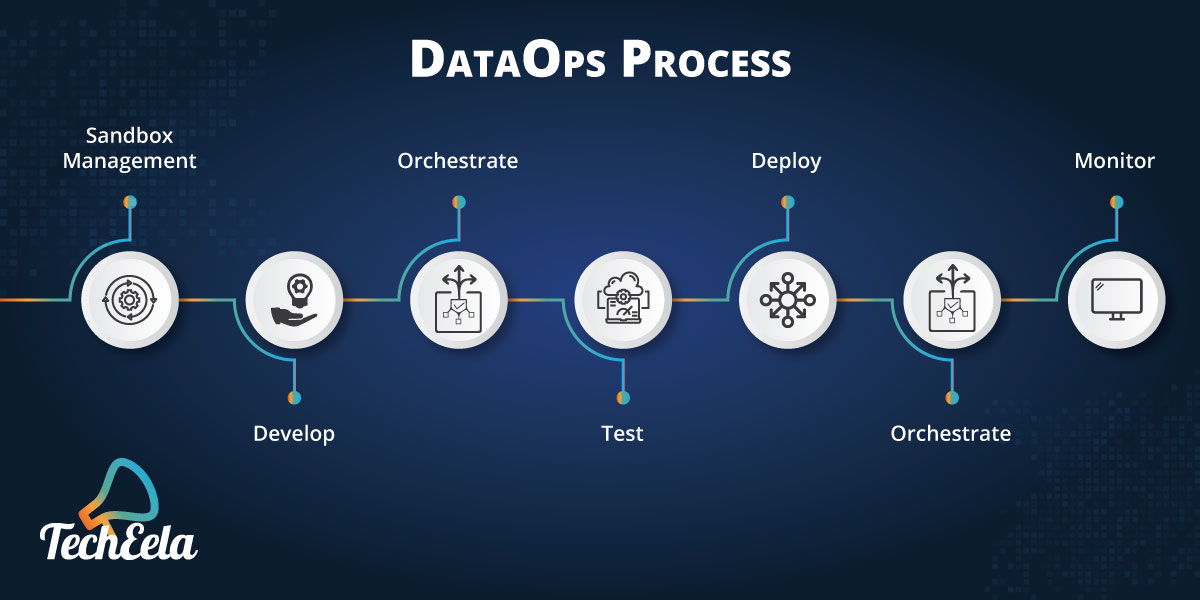
The DataOps architecture comprises of support for management and environment creation. This helps develop, test, and produce environments that ultimately help in orchestrating, test automation, and monitoring. Different agents in different environments act on behalf of the DataOps platform to configure and manage code, perform tasks, and give test outcomes, runtime information, and logs. This way the dataOps framework is able to work among different systems and tools. Apart from this, there are a number of other functions such as:
DataOps provides value to businesses apart from managing datasets. It runs with the help of elements and software related to data that help in running business processes. It is designed with the help of DevOps and many dataOps tools are used to provide easy services to the customers. Here we have listed nine popular dataOps tools for you:
They help provide data from different operational and application systems into data warehouses and provide better and useful analytical insights from the data. Some examples of data pipeline tools are:
These tools are for automated testing. They help in testing and comparing expected results v/s actual results from a software technique. Some examples are:
In data science model deployment tools, you basically use AI and ML and integrate their data models to make sound business decisions on the basis of these sets of data models. This step is very crucial in model life cycle as it’s the last step. Some examples of these tools are:
The main aim of DataOps is to design such an environment that is collaborative among the IT and data teams when they are working together toward creating value out of the data. Nowadays, we have an abundance of data available for our consumption, and to use this data creates valuable insights and derives profits. Some of the benefits of DataOps are:
There are an ample amount of data available at our disposal in the digital era, and it is increasing exponentially day by day. By using Data operations, organizations can create value out of this data in efficient ways.
Dataops promotes use of distinct kinds of analytical techniques. To guide data among different analytical stages, various ML algorithms are used to collect, process and classify data before its delivery to the users. Feed or suggestions are also provided quickly.
DataOps can help modify the complete process of work within the organization as it gives ample flexibility. Many new opportunities are discovered since the shift in priorities occurs. A whole new ecosystem is created in the enterprise where no barriers are separating different organisation departments. Collaboration between data engineers, managers, marketers, analysts and developers is done in real time to work together to achieve their corporate goals via planning and organizing. This helps in better customer-relationship and response time.
Data operations promotes strategic data management. Various departments in an organization work together to organize, evaluate and study data as well as the feedback provided by the users or customers and work for negotiating client’s needs. Automation procedures give long-term guidance and help to make business processes easier, efficient, and effective. You can also call it a two-way street between data sources and data users.
According to dataversity, the ultimate goal of DataOps is streamlining the design, developing, and maintaining apps based on data and analysis. The emphasis is on improving data management, the way products are designed, and coordination of the business goals with these improvements.
As the amount of data available to us is increasing day by day, new software, processes, and tools are required to extract valuable information from that data. IDC has anticipated that the data can increase by as much as 163 ZB by 2025, with structured data constituting 36% of the whole data. Present day’s software, tools, processes, and organizational institutions cannot handle such huge volumes of data and the output of data expected from it.
More employees will need access to these datasets to do their assigned tasks. A need for a philosophical shift will be required to remove barriers in the organization (cultural and organizational) to maintain a scalable, predictable, and recurring data flow. DataOps revolution is making the shift visible. It would be better for enterprises to improve their data operations team structure, processes, and tools so that they don’t lose their data in the near future.
This brings us to the end of the blog. DataOps is an agile development, process-oriented, and collaborative practice for managing your data. It focuses on better communication, automated flow of information, and integration among data managers and users within the organization. We have talked about eighteen DataOps principles that must be followed to improve the organisation’s data management practices. The DataOps architectural framework gives support for management and environment creation, which helps develop and test the production environments that ultimately help in orchestrating, test automation, and monitoring. We have also covered DataOps tools divided into three categories: Data Pipeline Tools, Automated Testing Tools, and Data Science Model Deployment Tools. Data operations come with problem solving capabilities, better data analytics, new opportunities and guidance for how a company should be run. As the volume of data increases exponentially, we need better and advanced data operations strategies to manage the large datasets without any data breach, leading to data loss.
More on Technology


